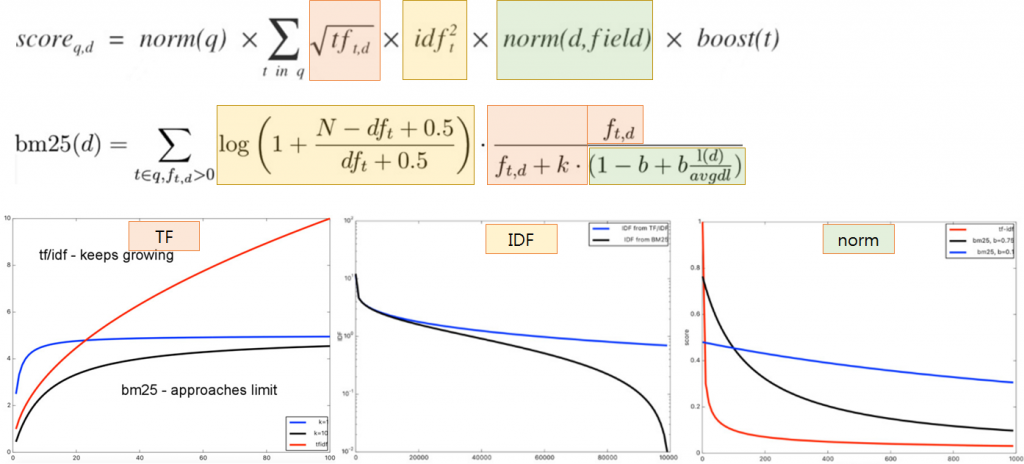
BM25
N = 문서의 수
df_t = 단어를 포함하고 있는 문서의 수
f_t,d = 문서에 포함된 단어의 빈도
tf : 단어 빈도
tf는 단어빈도로, 많이 등장할수록 문서의 검색 점수는 당연히 높아진다.
idf : 역문서 빈도
idf는 corpus에서 단어가 얼마나 많이 나오는가를 보는 수치이다. 여러 문서에 등장할수록 idf는 낮아진다.
norm : 문서 길이 가중치
norm은 문서길이 가중치로, 단어가 등장하는 문서의 길이에 대한 가중치로, 문서의 길이가 길수록 검색 점수가 낮아진다.
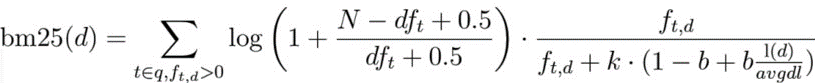
bm25의 검색 점수를 계산하는 수식은 위와 같은데, bm25에서는 각각의 파라메터들의 영향력이 어떻게 변화하는지 아래에서 확인할 수 있다.
tf는 단어빈도가 높아질수록 특정 값으로 수렴하고
df가 높아지면서 검색 점수가 0으로 수렴한다(idf의 영향력이 커진다) 불용어가 검색 점수에 영향을 덜 미친다.
norm의 경우에는 문서 길이의 영향이 줄어든다.
bm25에서는 문서의 평균길이(avgdl)를 계산에 사용하며, 문서의 길이가 검색점수에 영향을 적게 미친다.